


If an IT ticket is submitted, then it’s already too late. But what if you could get ahead of the pile up, reduce IT tickets, and solve issues before the tickets ever appear?
Digital workplace technology is evolving fast, fueled by the post-pandemic realization that IT is vitally responsible for the productivity and satisfaction of modern organizations.
But it’s not all going to plan.
Work from anywhere, digital collaboration, SaaS application adoption, hardware shortages, and the general acceleration of digital transformation have become the main driver of IT incidents and Service Desk spending.
The result?
Incidents are reaching critical mass, and Service Desk teams are stretched thin, leading to wasted resources, poor IT service delivery and frustrated employees.
More Budget =/= Less Incidents
The natural reaction to this crippling challenge is to increase Service Desk investment which essentially translates to hiring additional L1 and L2 Service Desk Agents. But that is not a sustainable strategy for two main reasons:
- The size of a Service Desk team has little correlation to the number of incoming incidents.
- Employees are still impacted by the same technical issues.
This means that, although the Service Desk can react and solve issues faster, incidents are still happening, and tickets are still being submitted because—most importantly—employees are still facing the same digital disruptions to their work, focus, and productivity.
In the end, hiring additional Service Desk agents is a big investment that doesn’t solve the root cause of the issue.
“The ITIL model is bankrupt, from what I’ve seen, its model is still based on the response coming back from the users. You don’t do anything—you wait.” – Jon Grainger, CIO, Slater & Gordon
Proactive Visibility
Proactive visibility refers to the ability to look beyond reported issues and detect issues before a ticket is raised or, better yet, before they can negatively impact employees. Because, for every reported incident, there are many more employees with the same problem “suffering in silence” and even more who are “at risk” but not yet impacted.

In this example, an incident was reported 4 times. In reality, 82 employees have the exact same problem but did not report it yet, 3266 other employees are at risk to be impacted by the same issue.
This is where predictive and preemptive analytics become interesting.
End-point Deep, Enterprise-Wide
This level of visibility is only possible with a deep, real-time, experience-level understanding of the digital employee experience. A single pane of glass to see how every employee, device, computing environment, application, and network function together and impact the employee experience.
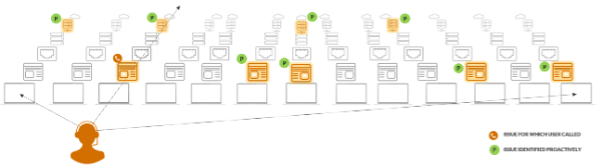
Instead of focusing on ticket resolution, IT can shift left and solve issues before impact. That is, detect non-reported issues across the entire organization and scale any troubleshooting across both impacted and non-impacted users.
“Nexthink allows us to be much more proactive… For my team, it allows us to free up more time and resources to help the business innovate.” – Jon Grainger, CIO, Slater & Gordon
Use Case: Detecting a Non-Reported MS Teams Issue Across 190 Devices.
Since their Work From Anywhere Policy started, a large European retail company struggled with collaboration tool issues. In fact, after 2 years, they were still facing a ticket overload which impaired their IT operations. Although they hired more than 3 additional L1 agents, ticket count remained unchanged.
The issue was not ticket resolution. It was the number of incidents.
This realization pushed them to take a more proactive approach, using Nexthink’s predictive analytics to identify the source of the root cause of the issue. See the solution in action in this use case demo video:
The result?
In less than a minute, they were able to understand and drill down into the specific root cause of an issue that was affecting over 100 devices. What’s more, because they discovered the root cause, they can not only fix the issue for every employee currently affected, but more importantly, they can prevent this issue from impacting any other employees in the future.
The future of incident management is not to fix more issues faster, It is to stop issues from happening in the first place by fixing them before they can reach critical mass. Using proactive visibility strategies, IT teams can identify issues at their root and push fixes across the entire digital ecosystem, not only reducing the number of IT tickets in the pile, but also eliminating the risk of future incidents as well.
Find out more at: Scale Your Service Desk: How 5 Organizations Stopped Incidents Before They Reached Critical Mass.
Related posts:
- Proactive IT 101: Learn How to Build a Proactive Service Desk
- 3 Ways to Enhance Your Service Desk With Real-Time Experience Data
- 3 Steps For A More Strategic Approach to Incident Reduction
- How IT Can Enable Smooth Digital Collaboration | Engagement and Automation
