
The 5 Spark Use Cases That Shrink Service Desk Demand

When service desks talk about transformation, what they usually mean is faster tickets, but what they really need is fewer reasons for tickets to exist at all.
Gartner predicts that by 2029, agentic AI will autonomously resolve 80% of common customer service issues, reducing operational costs by 30%. That shift points toward a zero-friction workplace, where employees do not have to navigate support just to get back to work.
For most IT teams, the opportunity starts with L1 volume. Much of it is predictable, these are issues IT already knows how to fix but still handles manually every day. Yet in many organizations, AI has been added around the existing workflow without changing the structure of support itself. Requests may move faster, but the intake model stays the same. The employee still opens a ticket, resolution still starts after the handoff, and familiar work keeps building up inside the queue.
Spark changes where resolution begins. Built on Nexthink’s real-time DEX telemetry and remediation engine, Spark has instant access to contextual data across the employee’s device, applications, and network, including signals such as device health, app performance, VPN access, and connectivity conditions. It uses that live context to diagnose the issue and execute IT-approved actions within existing controls. Instead of waiting for intake, Spark addresses repeatable issues directly, reducing unnecessary L1 interactions and removing work from the queue altogether.
1. Resolve recurring collaboration issues without opening a ticket
In most large organizations, day-to-day collaboration tools create a constant flow of small but disruptive issues that land with the service desk. The symptoms vary from case to case, but underneath it is usually the same handful of patterns tied to device state, network conditions, or user context. What feels new to the employee is often something the service desk has seen dozens of times before.
With Spark as the first point of engagement, the process no longer starts with a ticket. When an employee reports a collaboration issue, Spark looks at what is happening on that device in real time, whether the application is up to date, how the network is performing, and how the device is behaving overall. When there is an approved fix available, Spark runs it immediately within the boundaries IT has already set. The employee gets help in the moment, and the service desk does not have to restart the same time-intensive troubleshooting sequence for another familiar issue.
Here’s what that looks like in practice:
Spark detects degraded call conditions, checks network and Teams client state, applies the approved remediation path, and restores call quality in the same interaction.
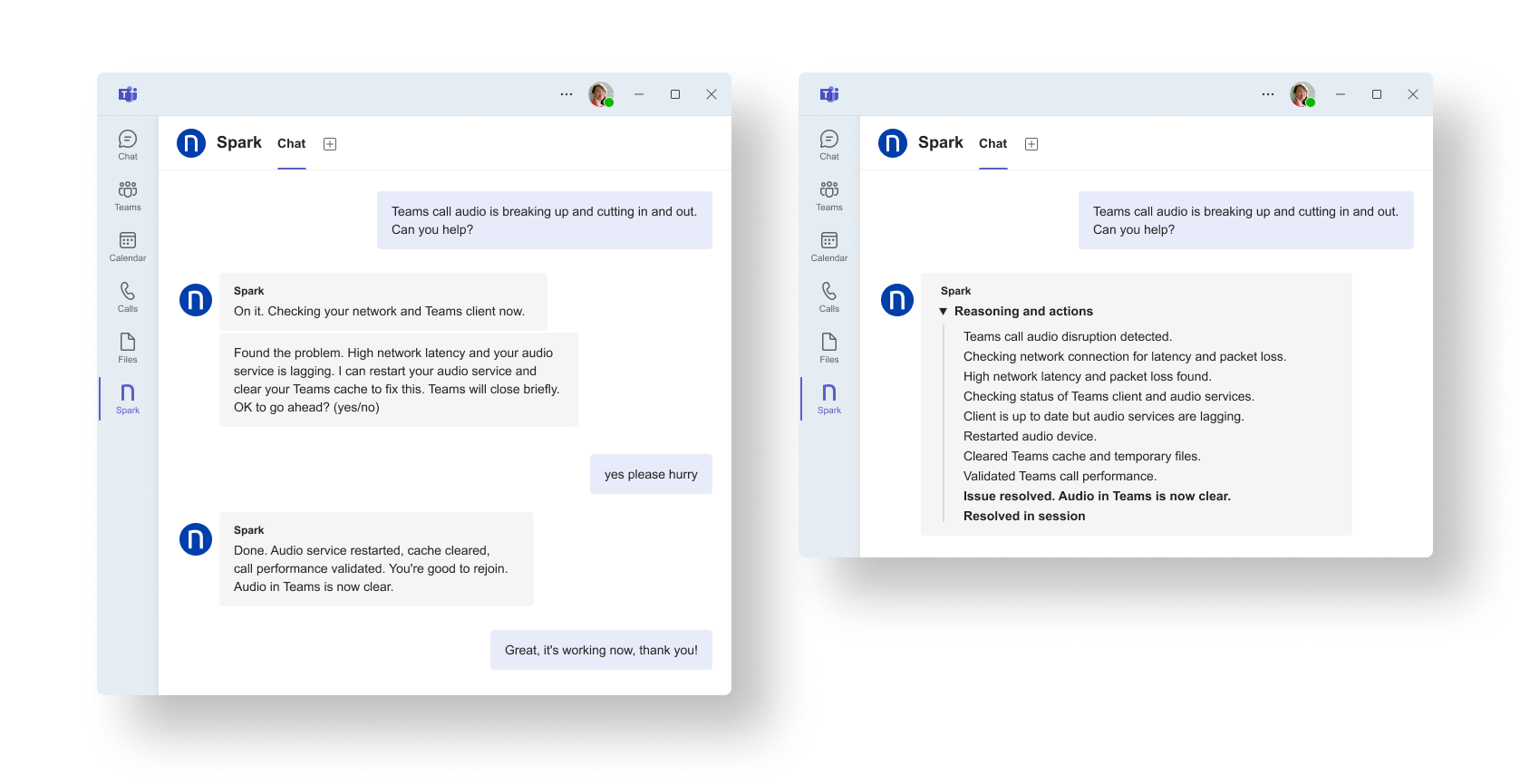
Over time, a category that once consumed recurring L1 bandwidth transitions into a largely autonomous flow, bringing down ticket volume and cutting out the repeated troubleshooting that used to follow.
2. Diagnose and remediate endpoint performance in session
Endpoint performance problems are common in large environments, particularly as devices shift from their original baseline over time. A classic example is slow startup or login. What should be a quick beginning to the day turns into several minutes of waiting as background activity competes for resources. In a traditional support model, an analyst starts with the user’s description and opens a ticket. Only then do they collect CPU, memory, disk, and process data before deciding what action to take.
Spark changes where that process begins because it operates on live endpoint telemetry and evaluates device state at the moment the employee starts the interaction. It can assess resource utilization, startup impact, and abnormal process behavior in real time rather than later. When defined thresholds are met and an approved remediation path is available, Spark executes the corrective action directly or initiates a structured workflow through Flow.
Here’s what that looks like in practice:
Spark identifies the background processes delaying startup, clears the memory load, and validates performance after remediation so the employee can get back to work without opening a ticket.
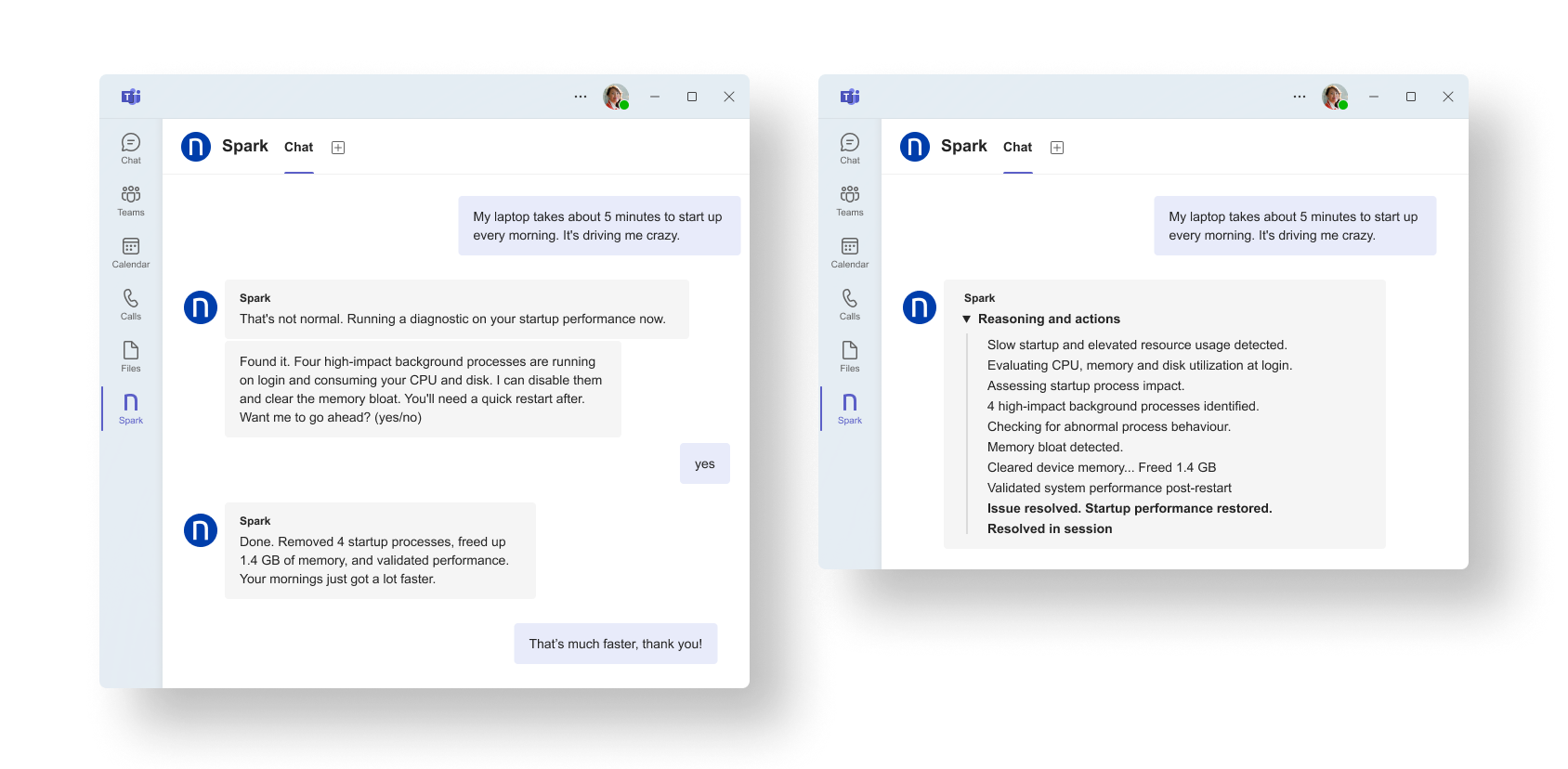
The result is that issues with a known diagnostic and remediation path can be addressed immediately, within IT-defined guardrails, without requiring manual data collection or the creation of a ticket.
3. Resolve repeat L1 issues before they reach the queue
Across most enterprises, a significant share of L1 volume maps to recurring categories: policy sync errors, basic configuration resets, entitlement refreshes, and client restarts. The persistence of this demand is typically a function of workflow design rather than technical complexity.
Spark embeds itself within existing self-service channels and responds when an employee asks for help. From that employee-triggered interaction, Spark attempts full resolution before a ticket is generated. It reasons over endpoint context, applies governed Agent Actions, and handles repeatable issues inside the support interaction itself. Instead of passing another familiar problem into the queue, IT can remove it from the queue altogether.
Here’s what that looks like in practice:
Spark detects a familiar Outlook client failure, runs the approved restart and cache-clear actions, and returns the application to a working state in-session.
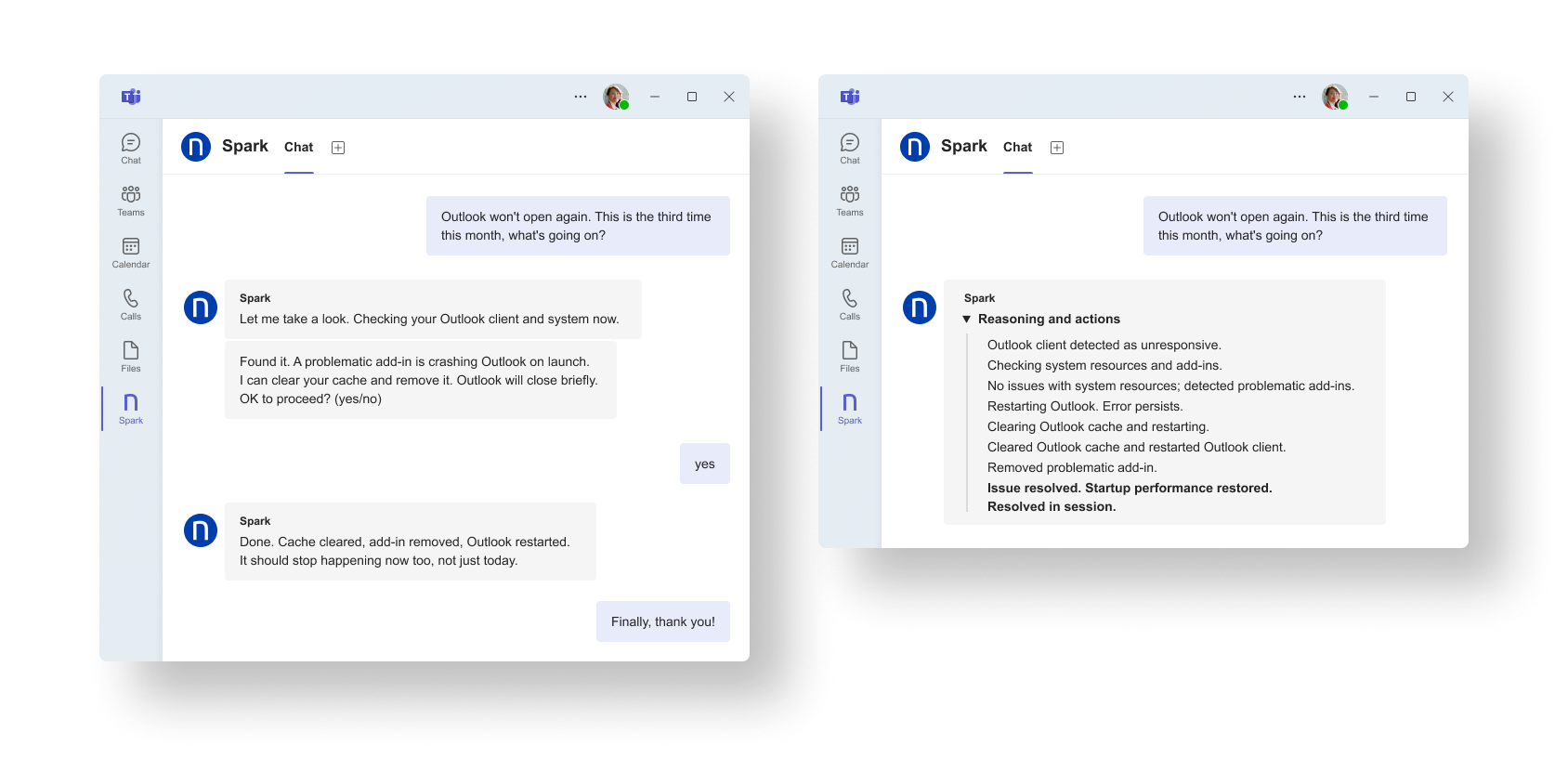
As predictable categories are resolved autonomously, ticket intake decreases over time. Zero friction becomes measurable in metrics rather than just aspirational language. The proof can be seen in lower L1 volume and improved first-touch resolution where human support is required.
4. Get employees back online when access breaks
Your employees’ opinion of IT is often defined by the moments that block work, such as access failures to sign-in loops. These are time-sensitive, high-friction moments that create difficult-to-resolve tickets because the employee cannot safely self-diagnose and the service desk is forced to start with questions rather than data.
Spark is designed for that moment. When an employee reports an access issue, Spark checks the current connection and device state in real time and follows the approved resolution path for what it detects. When the issue matches a known pattern, the employee can be unblocked immediately rather than entering a support process built around basic diagnosis and repeated handoffs.
Here’s what that looks like in practice:
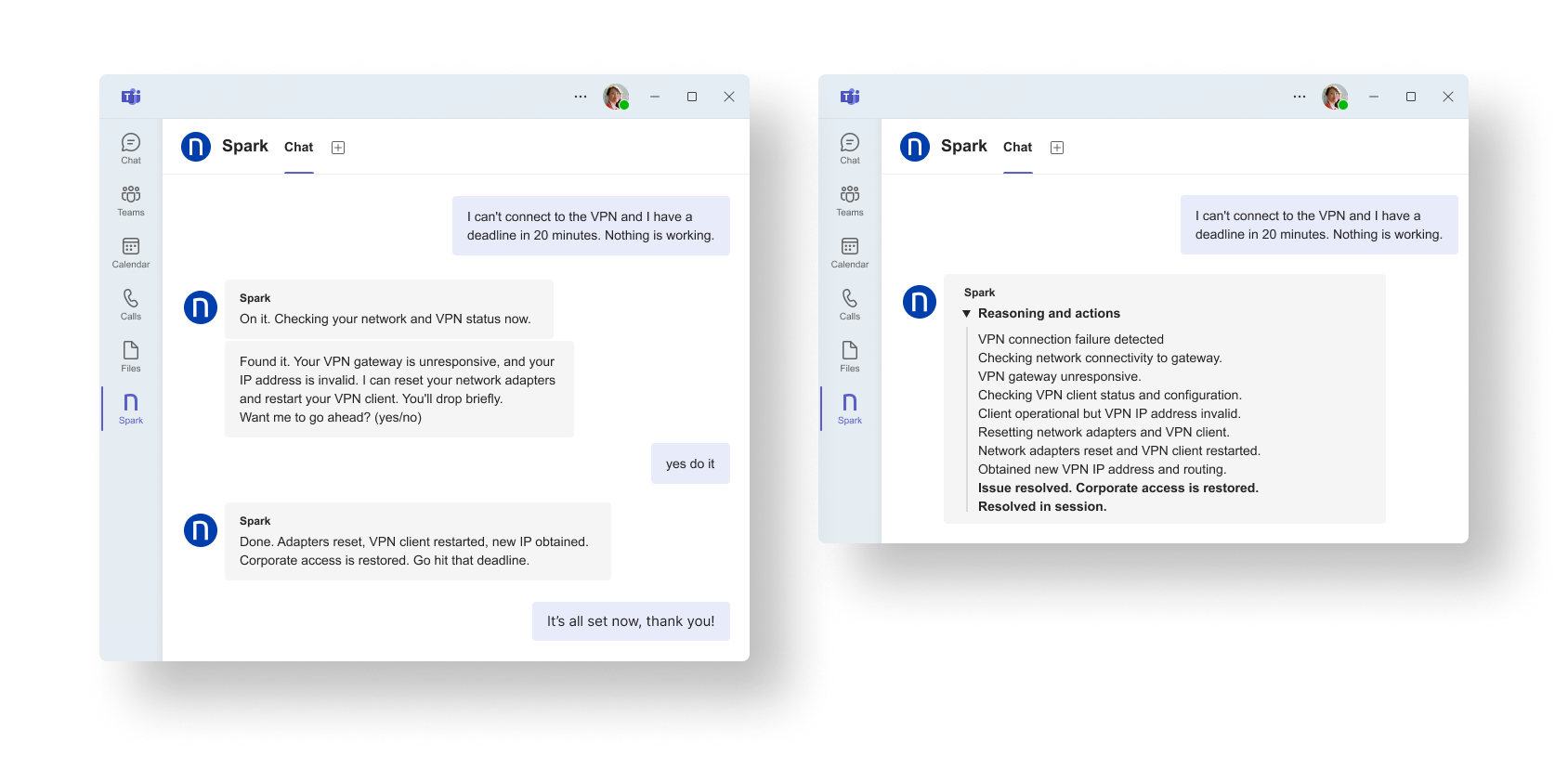
The impact is not only a better employee experience. It is a service desk that spends less time reconstructing known issues and more time on the work that truly needs human judgment.
5. Stop “my laptop is slow” from becoming a ticket
Performance complaints are a service desk fixture because they are real, they are subjective, and they are usually the result of gradual drift rather than one obvious break. By the time a ticket is opened, you are already in the slow loop: ask questions, gather logs, wait for a response, try a fix, repeat.
Spark short-circuits that pattern by starting with the live state of the device. When an employee reports sluggish performance, Spark can evaluate what is happening right then, identify the conditions that commonly cause slowdowns, and follow the approved remediation path. That changes the experience from a drawn-out support exchange into a direct resolution flow grounded in accurate, real-time data.
Here’s what that looks like in practice:
Spark detects live CPU and memory pressure, removes the source of resource contention, and confirms that system performance has recovered before the interaction ends.
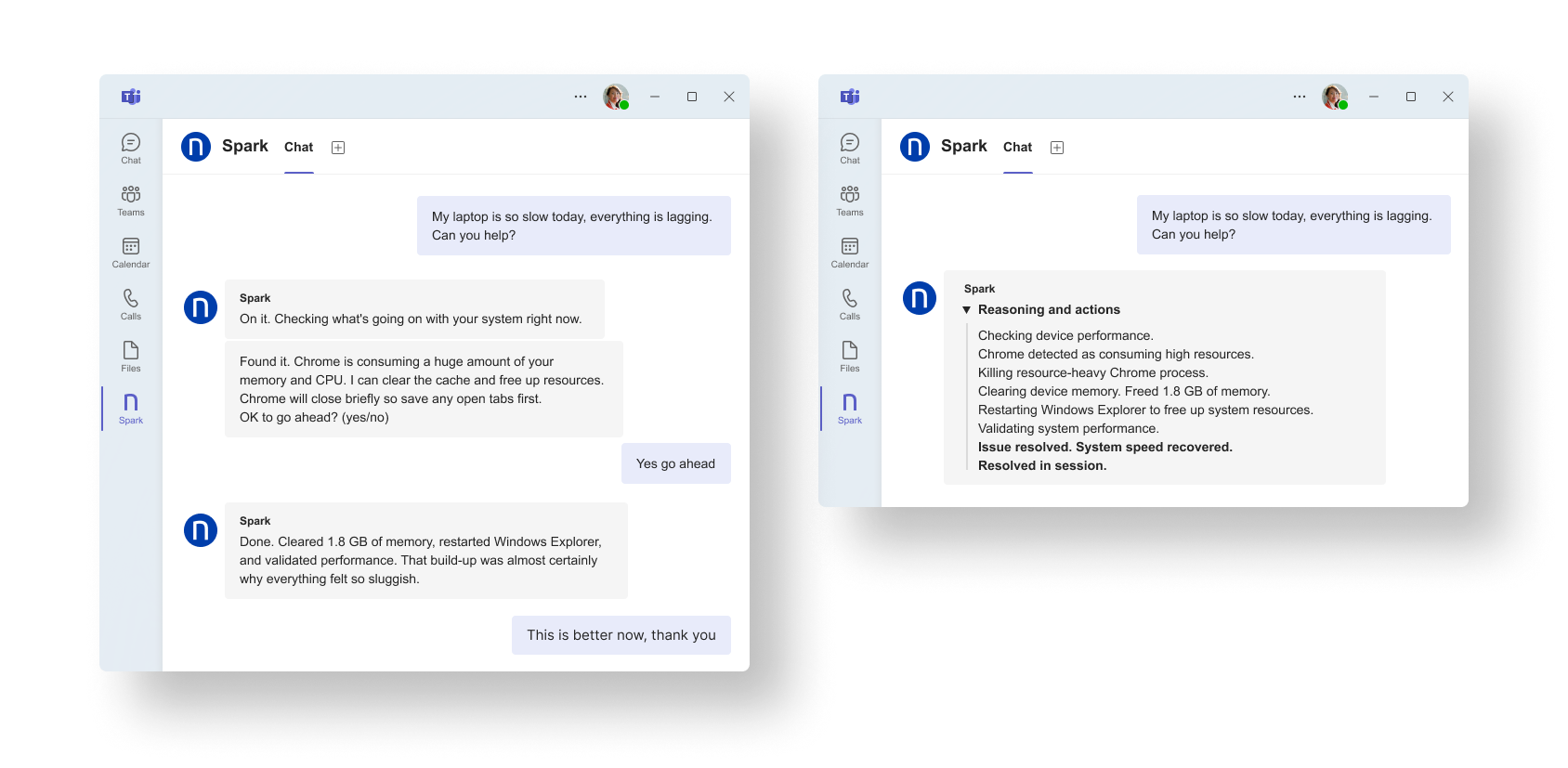
The strongest opportunities for Spark are the issues IT already knows how to fix but still handles manually every day. Slow-device complaints fit that pattern exactly. The endpoint signals already exist, and the remediation path is typically well defined. Spark uses that live context to recognize the pattern and execute the fix during the employee interaction, eliminating the need to generate a ticket.
Eliminate Your Most Repetitive Service Desk Issues
Spark can be applied to many of the recurring issues that consistently drive L1 volume, but these use cases only scratch the surface. In most environments, a relatively small number of repeatable conditions, collaboration instability, endpoint performance degradation, and configuration drift, account for a disproportionate share of service desk demand.
When those conditions are handled in real time, autonomously and without entering the queue, the impact is structural. Ticket volume drops, resolution becomes immediate, and service desk capacity shifts toward higher-value work instead of repetition. The question is no longer how quickly you can resolve tickets, but should those tickets even reach the service desk at all?
What could removing your top recurring L1 issues achieve for your team? To learn more about Spark, request a Nexthink demo today
