
Consumer Goods Company Saves Over 470 Hours and $23k of IT Support

Stable network connections are your business’s lifeline.
Vital elements of your modern workplace—such as hybrid working, SaaS application usage, and online collaboration—depend on good network performance, contributing to employee productivity and satisfaction.
But when network problems started to escalate for one of our customers, they realized they needed to look beyond their traditional network performance monitoring tools to solve the issue.

“82% of respondents said employees’ happiness on the job is significantly impacted by how well their workplace technology performs” – Harvard Business Review
Network Performance Monitoring (NPM) tools are not always the only source of truth.
Network Performance Monitoring (NPM) tools have always been—and always will be— key to understanding the health of your network. But when faced with a decentralized workforce, they fail to offer context about the relationships the network has with every other element in the infrastructure, such as endpoints, applications, services, or end-user perception.
This incomplete visibility leads to network blind spots where network connectivity issues and network performance issues will continue to go undetected, simply because you don’t have insight from your employee’s perspective.
And these blind spots have dire consequences. With incomplete visibility, you won’t know if your employees can’t collaborate effectively, which means tickets can start to escalate, and both your Service Desk and Network teams could struggle to keep up – wasting hours of support hours, especially when you have to solve each ticket or complaint individually.
But with the right tooling alongside your NPM solution, resolving network blind spots at scale is easier than you think. Here is an example.
The Situation
A European-Headquartered consumer goods company received a sudden peak in employee tickets and complaints about slow internet speed.
But, when the IT and Network teams, headquartered in Europe, looked through the lens of their NPM tool, all lights were green – there were no bottlenecks or obvious packet losses.
Yet something was clearly wrong.
So, IT’s knee-jerk reaction was to ask L1 support agents to reach out, individually, to each complaining employee and schedule a debug session – a huge time and productivity sink for a support desk team already stretched too thin.
Taking a step back, the Service Desk manager asked his team to use Nexthink to troubleshoot this headscratcher, hoping to reduce the workload on his team.
Contextual Visibility into a Device’s Connectivity
First, the network engineer opened a specific ticket and drilled down into the device’s network view in Nexthink to map out and understand its current status and relationship within the company’s network infrastructure.
Through the lens of the Network view, the problem was clear.
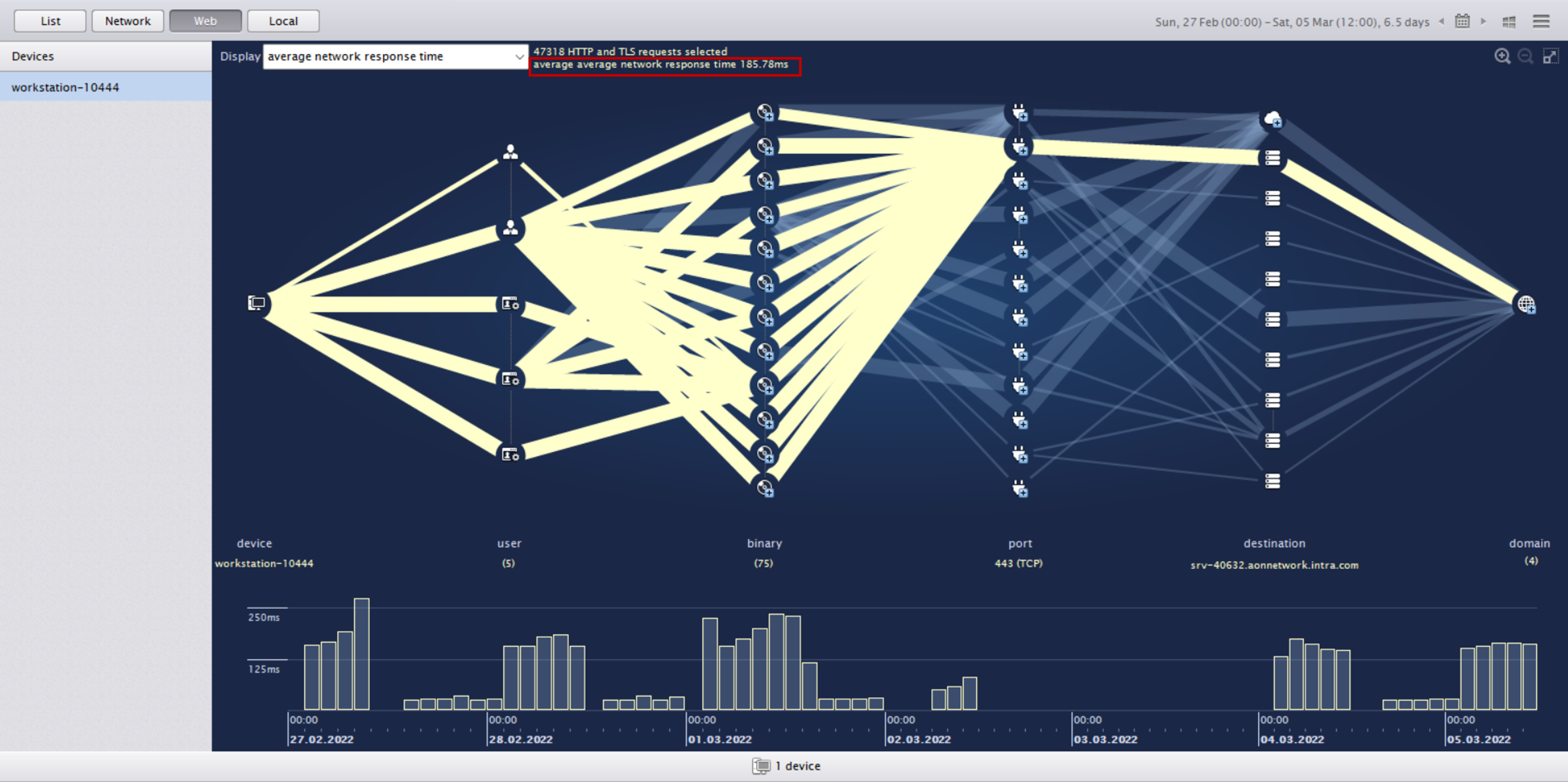
In the device’s network view, it was clear that DNS requests from Manila DC were experiencing high average network response time.
The DNS traffic from users connected to the Manila Data Centre was getting routed to the Google DNS of UK & US. This clogged up traffic, leading to abnormally high response times—almost double the average—thus explaining the slow speeds.
Drilling Down into Network Diagnostics
Now that the network agent had visibility into a single device’s problem, he could diagnose at scale. The agent didn’t need to diagnose individual tickets, he could actually identify everywhere this issue was occurring across the IT landscape. With Nexthink, the network agent easily diagnosed the issue enterprise-wide.
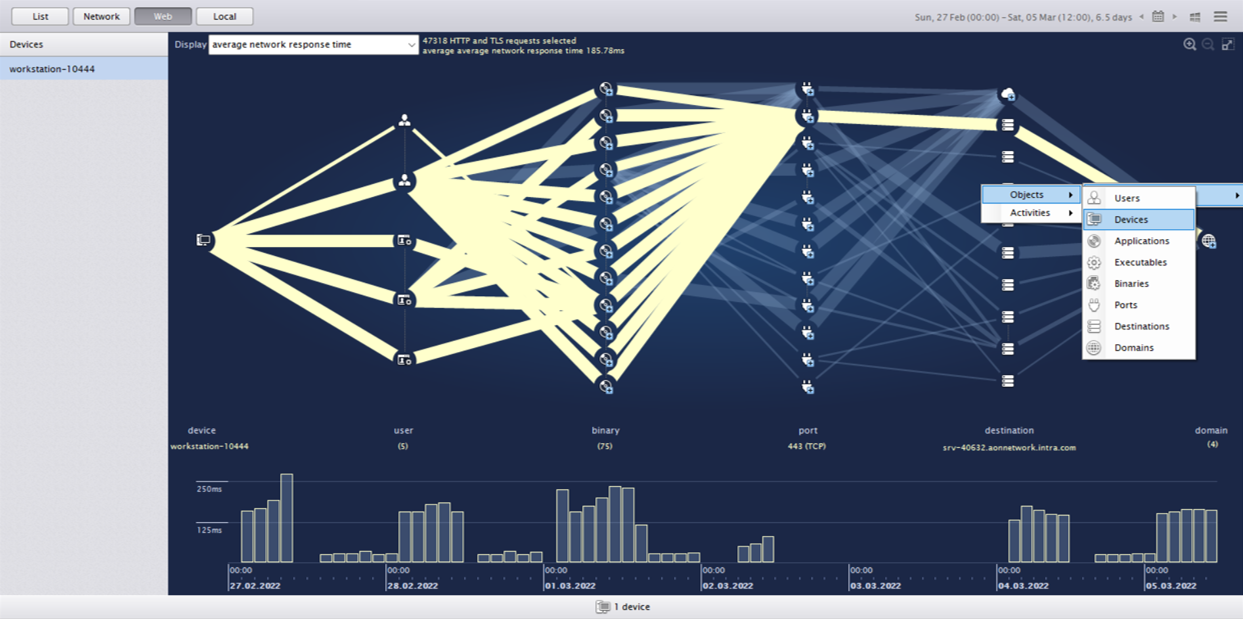
Using the drill-down capabilities of Nexthink, the agent was able to observe that many other users from the APAC region were also facing slow internet speed issues.
This diagnosis highlighted two substantial issues:
- Many devices in the APAC region were experiencing the same slow internet speed problem
- The majority of employees with slow internet speed did not submit a ticket – they were suffering in silence.
With that in mind, the agent realized that they had been faced with a serious blind spot that was leading to significant productivity and satisfaction drops.
Without wasting a second, the agent opened a ticket in their ITSM system and flagged it as urgent to their Network team, including all the relevant details gathered in Nexthink to fix the problem.
Quick Fix, at Scale
Based on the inputs provided, the Network team got to work on a fix that they could apply at scale. A configuration change was deployed to resolve to Google DNS of Manilla.
By applying a single fix to every device across the region, the support team did not need to schedule and resolve each and every individual ticket. What’s more, they resolved the root cause of the issue, so they could be sure these types of complaints would not happen again.
Tangible Results
The network and support team was able to report their successful identification, diagnosis, and fix of the issue with clear numbers:
- Improvement of Network Performance in 72% of the impacted devices.
- Remediation of the issue on 1,893 devices in a single, proactive fix applied at scale.
- At an estimated 15m of IT support time per device, the IT team saved 28,395minutes, or more than 470+hours saved of IT support time.
- At equivalent standard US rates, this saved the company $23,500.
- 0 incoming tickets related to this specific issue were reported in the following months.
294% average ROI over 3 years
"After investing in Nexthink, customers were able to see significant improvements in IT efficiency. This resulted in cost savings and more informed, data-backed decisions".
Related posts:
- How One Company’s IT Service Desk Used Automation to Reduce Incident Tickets
- How to Get Ahead of Recurring IT Tickets (Use Case)
- 5 Ways to Reduce the IT Incident Backlog Before Your Team Gets Crushed
- How to Keep Your Digital Devices Current | Engagement & Automation
