
Large Health System Reduces Critical Application Crashes by 90% via Nexthink Automation

Digital innovations have completely transformed the healthcare industry over the past decade. Today, clinical staff rely on applications to complete nearly every aspect of their day to day duties, from maintaining data privacy compliance to conducting telehealth.
That makes it even more important that these critical applications stay online. Application failures and crashes can have significant repercussions for the entire health system, from creating stress for clinical staff, to creating privacy vulnerabilities and even impacting the delivery of care. It is more important than ever that IT have the ability to proactively monitor and remediate application issues before they become impediments to care.
Read on to see how one US health system used Nexthink to reduce clinical application crashes by 90%.
The Problem
This health system knew they had a problem with application crashes across a whole range of applications. McAfee, athenaNet, and many other applications were crashing repeatedly, presenting significant challenges to clinical staff and patient experience. These crashes not only created frustrations for clinical staff, but also had the potential to expose compliance vulnerabilities or detract from patient experiences.
McAfee caused the most issues by volume, but the athenaNet crashes remained the most persistent. The team spent seven months trying to resolve the issue, even working with the vendor, but had yet to resolve it satisfactorily.
The Approach
With Nexthink in place, the team began by identifying the top 10 critical business applications that were crashing or otherwise causing significant disruptions to the care experience. They then divided the applications depending on how frequently the applications were crashing into the following four groups:
- Watch List (1-2 Crashes/Week)
- Fix Soon (3-5 Crashes/Week)
- Fix Very Soon (6-9 Crashes/Week)
- Fix Now! (10+ Crashes/Week)
This grouping helped with prioritization of the remediation efforts. The team quickly realized that McAfee was the least stable application in the environment. The source of the application crashes was a cached password on the affected devices. Once they identified the root cause of the issue, they used Nexthink automation to delete the cache password on all affected devices, resolving the McAfee crashes. A similar approach of proactive monitoring and automated remediation was taken for all applications on the list.
For the athenaNet issue, Nexthink showed that several connections from the installed application were going through port 9090, instead of 443. The application team then checked the file configuration present on the affected devices. Once they confirmed that the issue was the misdirected traffic, the faulty connections were immediately corrected, and application performance improved greatly.
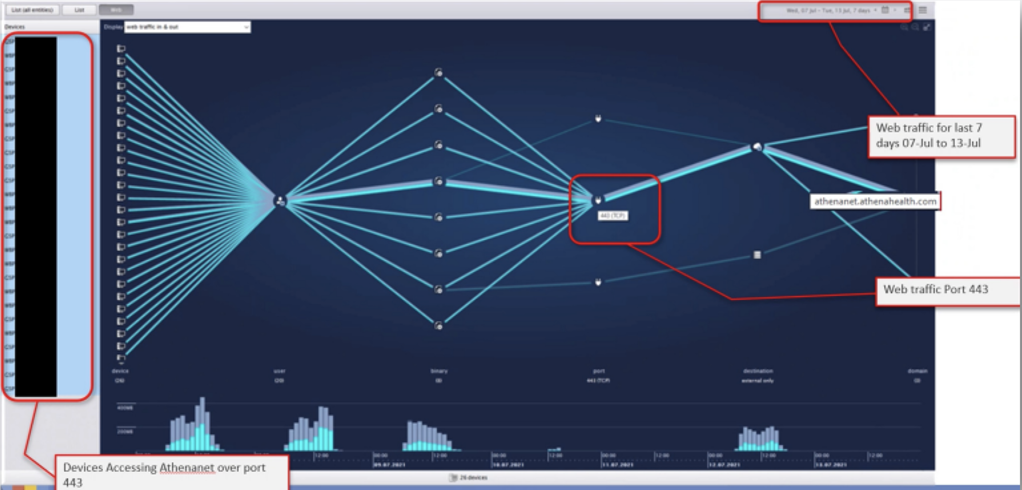
The Impact
Within one year, this health system had reduced crashes of business critical applications by 90%. The use of automation in this strategy meant IT wasted less time troubleshooting and had more time to address other issues. For the health system, this reduction in crashes meant physicians and nurses had fewer digital disruptions throughout their day, fewer stressful triggers, and were able to deliver patient care smoothly.
Ready to learn how Nexthink could help your team find and fix issues faster, so clinicians can focus on delivering care? Request a demo today.
Related posts:
- Clinical Digital Experience: Happy Staff, Healthier People, Lower Cost
- How Healthcare IT Improves Clinical Efficiency Through Digital Experience
- How To Improve the Performance of SaaS Applications using Nexthink
- US Hospital Saves $1.7M through Onsite Ticket Reduction
