
Comparing gRPC performance across different technologies

Source code: https://github.com/LesnyRumcajs/grpc_bench
What is gRPC Performance
gRPC is an open-source Remote Procedure Call system focusing on high performance. There exist several gRPC benchmarks including an official one, yet we still wanted to create our own.
Why would we torture ourselves doing such a thing?
- The implementation details for most gRPC benchmarks are not very clear. It’s hard to objectively judge two technologies performances if they are not written in the most optimal and idiomatic way possible, reviewed by experts.
- We wanted to compare performance across not only popular languages and their official gRPC libraries but also less popular languages that are still used by many developers across the world.
- Creating a benchmark is not that straightforward. For example, official benchmarks are expected to be run on a dedicated GKE cluster. We wanted a simple yet viable solution that could be run on most personal computers.
So with those points in mind, we created a completely open-source benchmark where everyone is welcome to contribute and which could be run with a single command, having only Docker as a prerequisite. Each implementation can be improved by the community so the results can be objective.
Community reception
We managed to collect several domain experts from different technologies – including Java, .NET, Scala and Erlang. Their contributions made the entire benchmark more realistic and objective. Occasionally, they even found a bug in the framework implementation!
The repository got quite popular on Reddit and Hacker News. It was also mentioned in a Microsoft Blog post. Using the feedback from all those sources, we strived to make the benchmark even better, e.g., including more statistics, making several aspects of the test suite configurable and adding a warm-up phase.
Setup
- The entire benchmark is based on Docker, and it is the only prerequisite. Optimally, the benchmark for gRPC performance should be run on a Linux machine to avoid introducing virtual machine uncertainty, which is present on Docker Desktop for Mac and Windows.
- For simulating the client-side we use containerized ghz, a gRPC benchmarking and load testing tool written in Go. Thanks to ghz, the client side can be parametrized with number of connections to use, number of requests to send concurrently, CPU usage limit, and payload size. Request rate can also be optionally limited. It is also possible to define the payload to be sent.
- On the server side, we run the containerized service in each programming language/gRPC library. The common ground for those implementations is a simple protobuf contract. The server side resources, CPU and RAM can be limited.
- Tests are run sequentially with optional warm-up phase to compensate for non-optimal startup, e.g., before JIT kicks in.
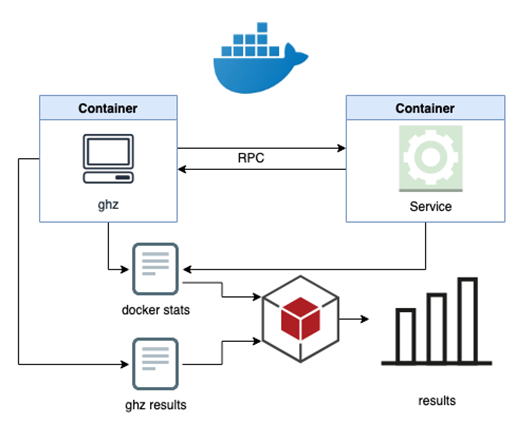
The stats from docker and ghz are then collected, parsed and combined by a Ruby script to be presented in a table with the language/library name, requests per second, average latency and 90/95/99 percentiles.
The process is summarized in the diagram below.
Challenges
During the benchmark development we bumped into several challenges that molded the final shape of the project.
Language-specific tricks?
In most programming languages you can do some tricks to improve your program performance at the cost of readability and/or portability. While those are interesting and would boost the performance of some implementations, we decided to prohibit them. The benchmarked service should be written in an idiomatic way (for the language used) so it can be easily maintained and extended. Just like we write our code at Nexthink!
The tested RPC
The work that is done with each request is a simple unary call – it’s basically an echo service. What a real-world service would do is most likely more interesting – like fetch an asset from the database, compute something non-trivial or act as in-memory cache.
It should be noted that the below metrics represent the gRPC/Proto layer only. In a real-world scenario, the service logic will most likely be more resource / time consuming. We are not claiming you’ll reach huge performances using Rust, C++ or Scala for your next micro-service project.
We decided to go with the simple approach to:
- Facilitate the implementation. With this approach we could start with quite a lot of technologies by just grabbing the implementation from their respective examples.
- Precisely test the implementation of a gRPC library. Adding a complex operation would make the benchmark verify not the library but the performance of this complex operation in each technology.
Creating an objective environment
This one is more challenging than it seems. We needed to supply a common environment for all technologies to perform well. Adding a warm-up phase to negate the initial cost of JIT (which makes sense as most server applications are long-running processes) or exposing parameters such as to fine-tune the benchmark for one’s specific needs were important pieces of our setup.
Hardware limitations
With the hardware at our disposal and the concept of running the entire benchmark solely using the local machine, we were able to only benchmark services up to the limit of 2 CPUs. To generate enough traffic, we had to use 9 CPUs on the client side.
Benchmark results
In this section we illustrate the benchmark results published in our github wiki. Before diving in, we must talk about two fundamental aspects: the hardware and the workload.
Hardware
All tests were run on the following physical machine:
- Processor: Intel Xeon CPU E5-1650 v3 @ 3.50GHz
- Memory: 32GB, DDR4 2400 MHz
- Operating system: Ubuntu 18.04.5 LTS (GNU/Linux 4.15.0-112-generic x86_64)
Workload
We ran two tests to benchmark the server implementations using one and two CPU cores. Aside from the server’s CPU, the benchmark’s configuration is always the following:
- Benchmark duration: 120s
Duration of the benchmark - Benchmark warmup: 30s
Time during which the server processes requests before the start of the real benchmark - Server RAM: 512MB
Maximum amount of memory used by the server Docker container - Client connections: 50
Number of connections to use; concurrency is distributed evenly among all the connections - Client concurrency: 1000
Number of request workers running - Client QPS: 0
Requests per second rate limit (0 = no limit) - Client CPUs: 9
Maximum number of CPU cores used by the ghz client - Request payload: 100B
The results
In this section we analyze the throughput and the latency percentiles of various gRPC server implementations written in the most popular programming languages. In case a given language has more than one implementation, we pick the most efficient one.
The full results can be found here: https://github.com/LesnyRumcajs/grpc_bench/wiki/2020-08-30-bench-results
Single core server

The first place in this test is taken by the rust (tonic) gRPC server, which despite using only 16 MB of memory has proven to be the most efficient implementation CPU-wise.
Then, we have the group of ‘heavily optimized’ garbage collected implementations: Scala (240 MB of memory), Java (105 MB of memory) and .NET (93 MB of memory).
At the bottom, not surprisingly, we have a trio of scripting languages: Python, Ruby and PHP. Note that the C++ server has the second lowest memory consumption (8 MB) and a more than decent throughput. The most lightweight server is the Swift gRPC taking only 6 MB of memory.
All language implementations were fully using the allocated core.
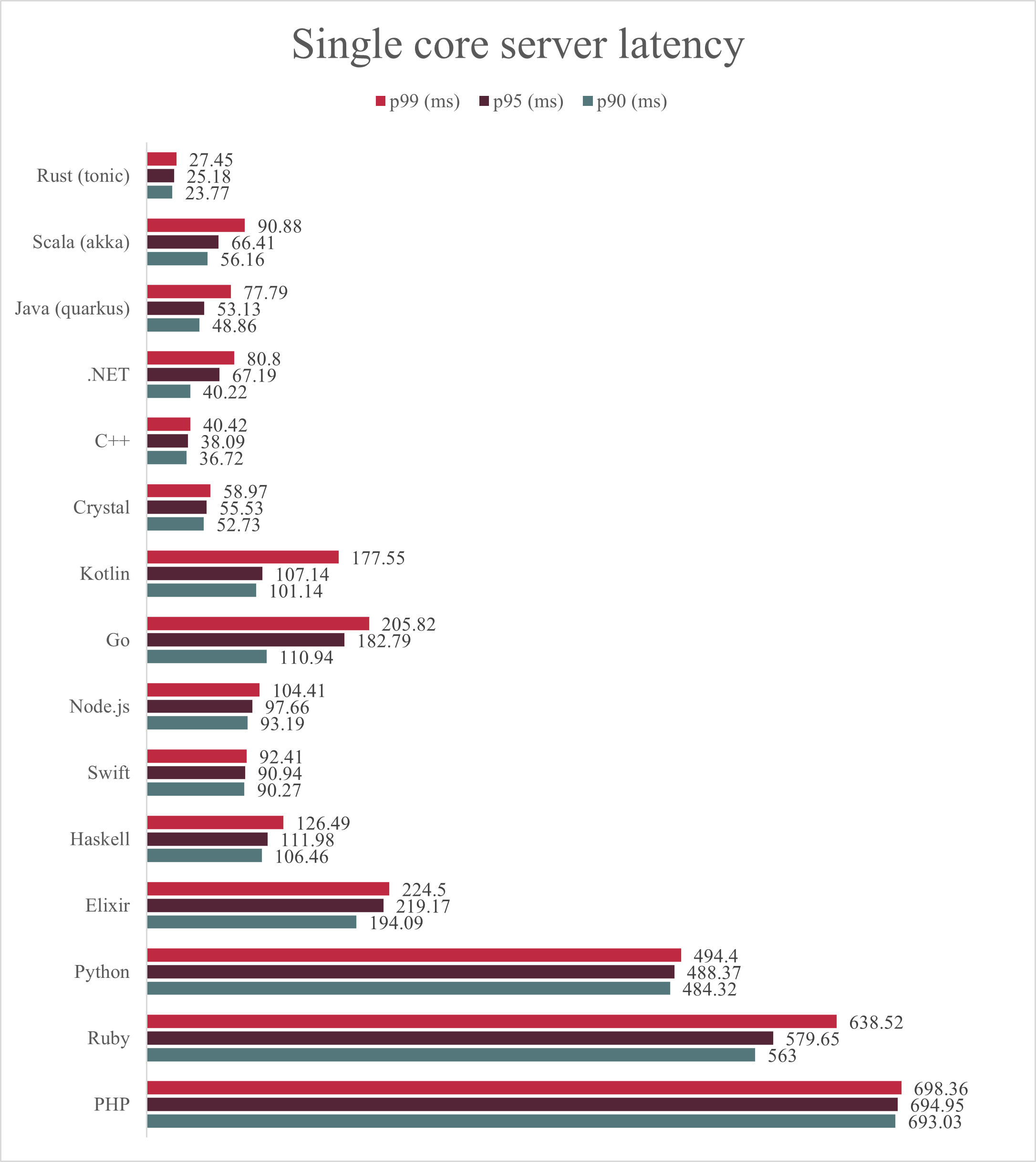
The latency measurements follow the same pattern as the previous graph. In general, servers with higher throughput have also lower latency; exceptions are Scala, Kotlin and Go, all having a significant spike in p99 latency (meaning, 99% requests should be faster than the given latency).
Two cores server

When we allocated two CPU cores to each server, the benchmark produced vastly different results. Scala is now on top, albeit with a not excellent memory consumption (242 MB). At the next four spots, we have both garbage collected languages and manually memory managed languages. The only difference is the memory usage: C++ and Rust stay quite low, at around 10-30 MB, while Java and .NET reach 200 and 150 MB respectively.
Go’s performance improved drastically with the addition of more CPU cores. On the other hand, Node.js is limited by the fact it can’t use more than one core.
At the bottom there are scripted languages again. Some of them can’t really make use of an extra CPU (Python, Ruby) or are quite inefficient (PHP).

Even on multiple cores, the fastest servers have a good latency profile as well. C++ and .NET are doing particularly good with a p99 latency of only ~42 milliseconds. Rust (tonic gRPC) is instead showing the worst latency profile than comparable .
Slower implementations are overwhelmed and appear to be unable to cope with the number of requests.
Alternative workload results
To show how much the benchmark is influenced by the workload, we have run two additional tests with tweaked configurations.
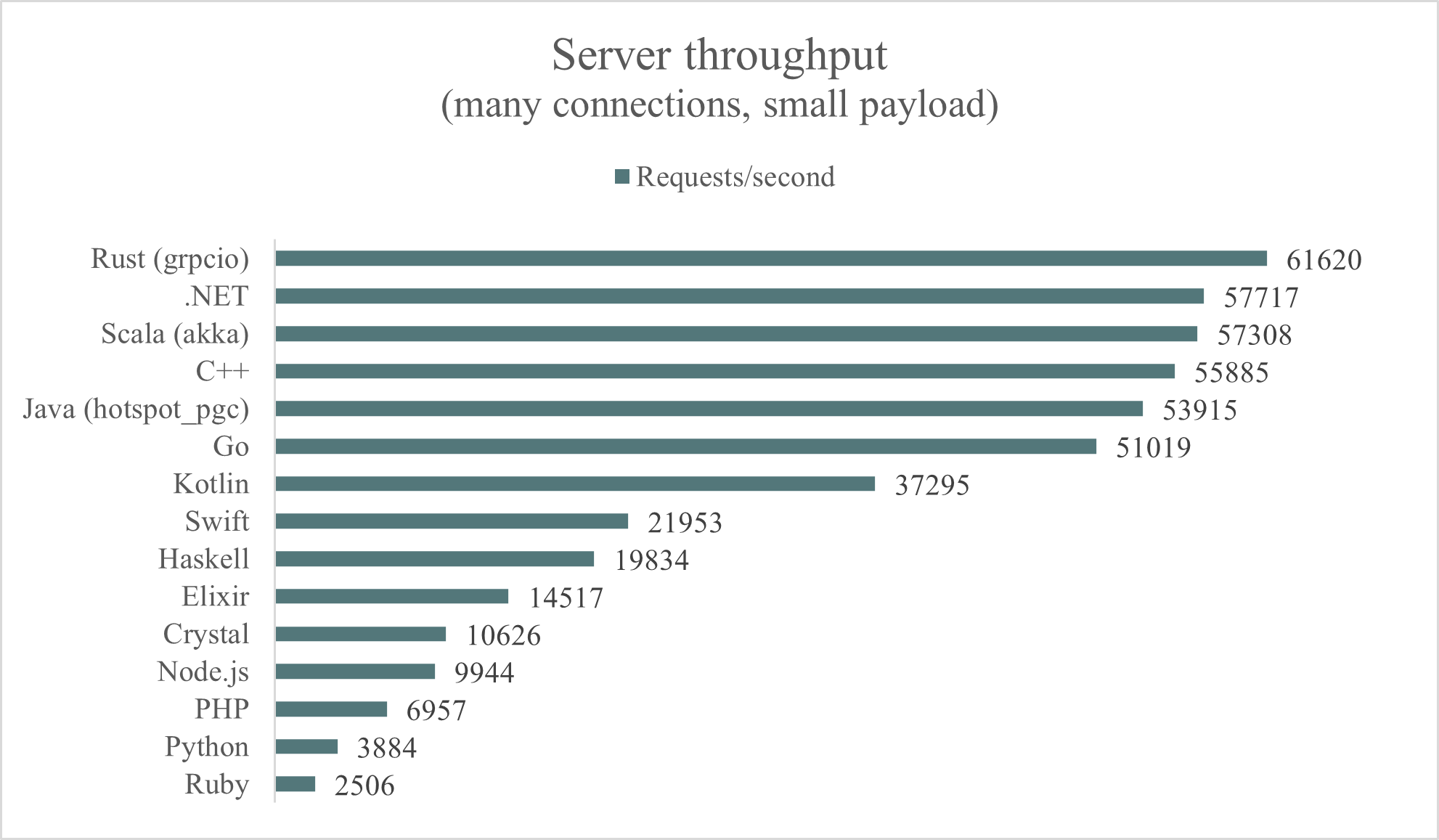
The alternative test tries to emulate a workload with many clients making very few small requests each:
- Warmup (30s) and duration (60s)
- 3 server CPU cores
- 250 client connections instead of 50
- A concurrency value of 500 instead of 1000
- Payload size remains 100B
The second test simulates an on-demand routine that handles a few gRPC connections sending large payloads:
- No warmup
- The test duration reduced from 120 to 30 seconds
- 3 server CPUs instead of 2
- 5 client connections instead of 50
- A concurrency value of 25 vs 1000 in the previous tests
- Payload size increased from 100B to 1KB
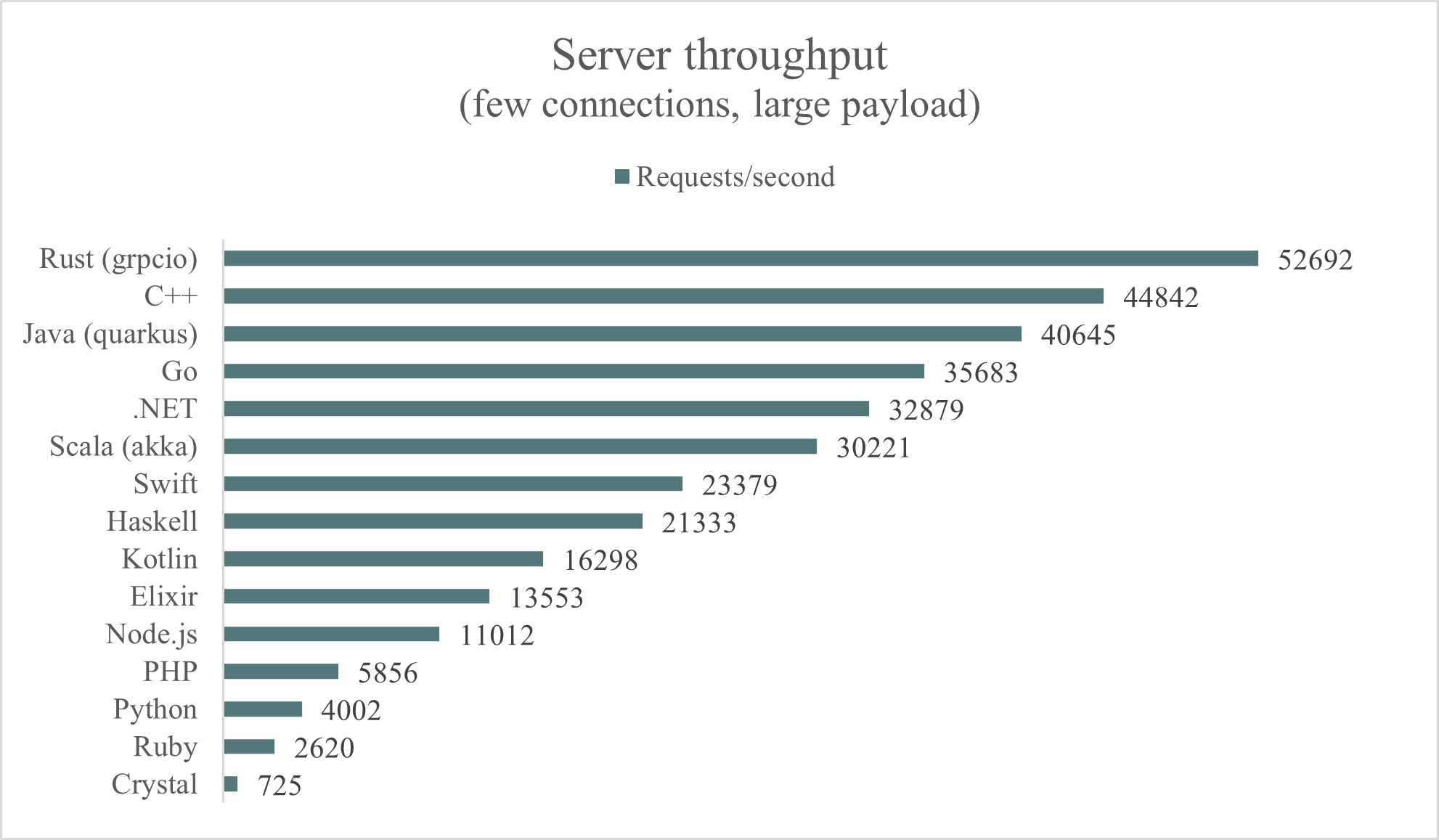
As you can see the results change a lot depending on the workload.
gRPC Performance Test Summary
What did we learn?
Benchmarking is hard. Providing a common framework able to objectively compare different technologies with all their quirks requires collaboration with experts.
On the topic of gRPC performance, it is often more influenced by the library implementation than the programming language used, an example being Scala Akka achieving 1800% better performance with just a version bump. Therefore, if you care about efficiency of your service, you should not only carefully pick the programming language, but also one of the many libraries the ecosystem offers.
Nevertheless, we can draw some general findings in terms of gRPC performance:
- Interpreted languages like Python, PHP and Ruby don’t perform well and should be used with care if you want to limit your cloud costs.
- Rust implementation provides best latency and memory consumption for a 1 CPU constrained service. It makes it a great candidate for services that are supposed to horizontally scale. On the other hand, scaled vertically it does not perform as good as Scala Akka.
- Languages with JIT compilers (Java, Scala, Ruby) should have a warm-up period to achieve optimal performance. This makes them less suitable for on-demand workflows but great for continuous uptime.
It is important to note that you should benchmark with the workload and hardware you expect to have in your production environment. Going beyond, proper documentation and active community is no less important when it comes to choosing your direction. After all, you don’t want to end up building your product on a technology that may get abandoned within a year or two.
Related posts:
- Smarter CPU Testing – How to Benchmark Kaby Lake & Haswell Memory Latency
- Expose GRPC Service Via Gateway/Reverse Proxy
- Natural Language Interfaces to Databases (NLIDB)
- Let’s Break Down Marble Testing Redux-Observable Epics
